Overview
MIT 6.5840, formerly known as 6.824, is a graduate-level course at the Massachusetts Institute of Technology (MIT) that covers distributed systems. The course presents abstractions and implementation techniques for engineering distributed systems, with major topics including fault tolerance, replication, and consistency. The course also includes several programming labs that give students hands-on experience with building distributed systems.
The labs for the course are using GO lang and as follows:
Lab 1 - My Lab Report: MapReduce - In this lab, students implement a MapReduce system, which is a programming model for processing large data sets in parallel.
Lab 2 - 2A: My Lab Report: Raft - In this lab, students implement the Raft consensus algorithm, which is used to ensure that multiple servers in a distributed system agree on the same values.
Lab 3: Key-Value storage based on Raft - In this lab, students build a fault-tolerant key-value storage system using the Raft algorithm implemented in Lab 2.
Lab 4: Sharded Key-Value storage - In this lab, students extend their key-value storage system from Lab 3 to support sharding, which allows the system to scale horizontally by partitioning data across multiple servers.
These labs provide students with practical experience in implementing distributed systems and help them understand the challenges and trade-offs involved in building such systems.
LAB 1: Map-Reduce Lab
Introduction
This introductory lab serves as a warm-up exercise to familiarize students with distributed systems, prepare them for reading academic papers, and encourage them to search the web for information. The lab involves implementing a MapReduce system for a distributed word count program.
Thinking Process
Read the academic paper
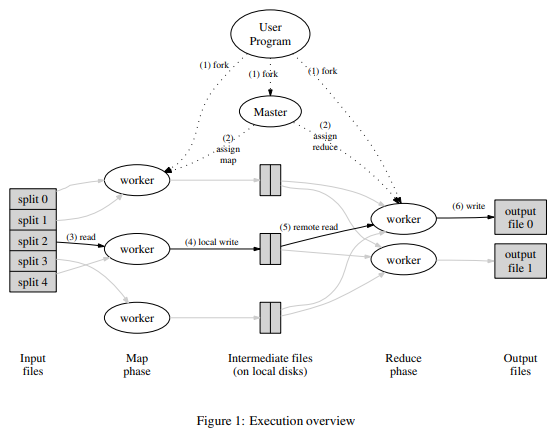 This is an overview of the MapReduce system, which consists of two types of servers: a master/coordinator and multiple slave/workers.
This is an overview of the MapReduce system, which consists of two types of servers: a master/coordinator and multiple slave/workers.
The basic workflow is as follows:
- The master receives an input consisting of an array of strings representing the names of the files to be processed, and an integer representing the total number of reduce tasks.
- The program start with a map phase, the master distributes map tasks to the workers, each with a filename to process.
- The workers create intermediate files and report back to the master when they are done.
- After all map tasks have been distributed, the master checks if all map tasks are completed and redistributes any incomplete tasks after a period of time (10 seconds in this lab). This may be necessary due to network failures or worker machine failures.
- Once all map tasks are completed, the master distributes reduce tasks to the workers.
- The workers then read the intermediate files and create the final output files.
Undersanding Map and Reduce function
Understand Responsibility of map and reduce function The pseudocode are as follow
Map
1
Map("I am potato I am chick") -> [{"I",1},{"am",1},{"potato","1"},{"I",1},{"am",1},{"chick",1}]
Reduce
1
Reduce({"I",1},{"am",1},{"potato","1"},{"I",1},{"am",1},{"chick",1}) -> [{"I",2},{"am",2},{"potato","1"},{"chick",1}]
Understanding intermediate files
Quotes from paper:
Periodically, the buffered pairs are written to local disk, partitioned into R regions by the partitioning function.
When I first read this line, I thought it meant that there would be a total of R intermediate files. However, upon further examination, I realized that it actually meant that each map task creates R intermediate files.
When a reduce worker has read all intermediate data, it sorts it by the intermediate keys so that all occurrences of the same key are grouped together
Initially, I thought this meant that each worker would need to read ALL the data and sort it, which didn’t make much sense. But after figuring out the actual meaning of the line, I gained a better understanding of the MapReduce system.
For example, consider a scenario where there are 8 input files and a total of 10 reduce tasks. In this case, there should be at least 8 map tasks, each of which creates 10 intermediate files, resulting in a total of 80 intermediate files. I will discuss more in the following.
Hashing
hash function provide by lab
1
2
3
4
5
6
7
// use ihash(key) % NReduce to choose the reduce
// task number for each KeyValue emitted by Map.
func ihash(key string) int {
h := fnv.New32a()
h.Write([]byte(key))
return int(h.Sum32() & 0x7fffffff)
}
Declare filename of intermediate file
1
ifilename := fmt.Sprintf("mr-%d-%d", w.Task.TaskId, i)
The reason that a worker need to create R (Total number of reduce task) is to ensure that the same word in different files will be processed during the same reduce task. Using the above example of 8 input files and a total of 10 reduce tasks, the same word appearing in multiple files will be placed into the same segment by having the same last digit in the filename, such as mr-x-z and mr-y-z. The distribution is handled by the hash function.
System Design
Fault-tolerance
Map-reduce system allows failure for worker but not master. So it is a bit simpler as I just need to handle fault tolerance for worker.I think of 2 solution to handle fault tolerance, one is keeping a heart beat message to make sure the worker are still working, another which I chosen to implement is a resend if timeout.
1
2
3
4
if c.taskTrackers[i].status != 2 && //the task is not done
time.Now().Sub(c.taskTrackers[i].start) > 10 * time.Duration( math.Max(float64(c.taskTrackers[i].Redistribute),float64(1))) * time.Second {
//resend
}
Eventhough the lab mentioned keeping the resend timeout as 10s will be enough, I impleement a resend timeout calculation of 10s * times of distribution to make sure the resend happen dues to failure instead of it really does need more than 10s to handle the task
Worker-ID
I originally did thought of implementing a worker registry system and distribute an ID before it start work, but it seems a bit redundant as long as the master could keep track the status of task will be good enough. (A task-based implementation instead of worker-based implementation)
Thoughts/ What I learned
It is quite surprising that when I realized the map-reduce system involves a single point of Failure which the whole system will be out of service when the master is in a failure. This also make me realize the strength of raft algorithm as it could still work as long as there are still n/2+1 server instance working in the system.